Classical linear codes#
There are many different ways of of protecting classical information from noise. The simplest and nicest such processes are built from linear codes. Quantum error-correcting codes are also often built from classical linear codes, which is a strong motivation to study such classical codes.
Treating information as vectors#
The classical error correcting model we discussed earlier was as follows.

Information here is in the form of bit strings. In line with our discussion in the binary field, we will now treat these as elements of vector fields over the binary field. Let us now define each of these vector fields.
The message space#
The first vector field is the one that contains the message. For the type of codes we will study, the length of the message is a fixed number, which we denote by $k$. If the information to be sent is longer, than we break it up into blocks of length $k$, and then treat each block as its own independent message. In the repetition code example, the blocks were of size 1.

Keeping this in mind, we have the following definitions.
The information to be protected is a bit string of length $k$, and each such string is called a message.
The message space is the vector space with all $2^k$ possible messages. This vector space is denoted as $\mathbb{F}_2^k$.
For the repetition code, $k=1$. This means the elements of the repetition code are $\set{0,1}$.
The codespace and the code#
As in the repetition code, for linear codes each message is transformed into a longer bit-string before being transmitted. This longer bit-string is called a codeword, and the transformation from message to codeword is called encoding the message.
A message is transformed or encoded to a codeword, which is a bit string of length $n$.
Codewords are of length $n$. There are $2^n$ strings of length $n$, but there are only $2^k$ valid codewords - one for each possible message. Therefore, there are two vector spaces here.
The codespace is a $n$-dimensional vector space, labelled $\mathbb{F}_2^n$. We require that $n \ge k$.
There is no typo here. Codespace is written without a space usually. For the repetition code, the codespace consists of all length-$n=3$ bit strings, $$ \set{000, 001, 010, 011, 100, 101, 110, 111}. $$
The second vector space is the the subspace of the codespace that actually contains the valid codewords. For the repetition code, this is the two codewords $\set{000, 111}$.
The code $\vecs{C}$ is a $k$-dimensional subspace of $\mathbb{F}^n_2$. Compactly, we can write $\vecs{C} \subset \mathbb{F}_2^n$.
So code is just the name for the vector space in which valid codewords live. The relationship between the three spaces is shown below.
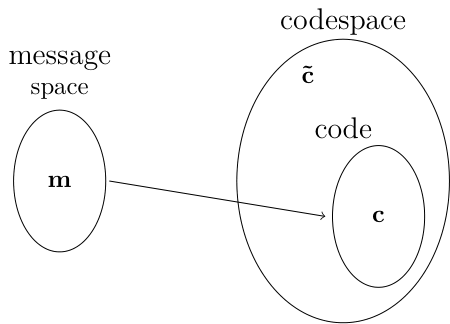
In the repetition code, the message $\vec{m}=0$ lives inside the message space. It is mapped to the codeword $\vec{c}=000$, which lives inside the code $\vecs{C}$. If $\vec{c}$ gets distorted by noise in the channel, then it gets transformed into the corrupted codeword $\vec{\tilde{c}}$ which lives inside the codespace by outside $\vecs{C}$
Why error-correcting codes are called code?#
To specify an error-correcting code, we need to define the following three things.
- The dimension of the message space, k.
- The dimension of the codespace, n.
- The code $\vecs{C}$.
Here the code $\vecs{C}$ is the non-trivial part, so error-correcting codes are just called code. This abuse to terminology is not too bad, as it is usually clear from context whether we are talking about $\vecs{C}$ or the entire error-correcting code.
Error-correcting codes are usually labeled as $[n,k,d]$, where distance $d$ is something which will be defined later. This is an underspecification as there can be more than one code with the same $n,k,d$ but different $\vecs{C}$. However, these parameters are usually sufficient within context to identify the code.
Question: What is the label $[n,k,d]$ for the repetition code? It has distance $3$.
Encoding process#
The definition of a code given above is quite abstract. To encode messages and decode corrupted codewords we need a more concrete definition that gives well-defined calculational procedures. This is done by given an explicit definition of $\vecs{C}$.
For any code, we can identify a basis set of $\vecs{C}$. For instance, for the repetition code, the basis set is $$ \begin{pmatrix} 1 & 1 & 1 \end{pmatrix}, $$ where we are now writing vectors as row matrices instead of bit string. In general, there will be $k$ such vectors because the subspace is $k$-dimensional, and each vector will be of length $n$. We can collect these $k$ vectors into the rows of a matrix, called the generator matrix.
The generator matrix, $G$, is a $k \times n$ matrix whose rows are a basis of the code $\vec{C}$.
For the repetition code, a generator matrix is \begin{equation} G = \begin{pmatrix} 1 & 1 & 1 \end{pmatrix}. \end{equation}
Any message $\vec{m}$ can be encoded into a codeword $\vec{c}$ using the generator matrix. The codewords of the code are all in the row space of its generator matrix $G$, i.e. the set of codewords is \begin{equation} \set{c = \vec{m}G : \vec{m} \in F^k_2}. \end{equation}
For the repetition code, we find the codewords to be \begin{align} \begin{pmatrix} 0 \end{pmatrix} \begin{pmatrix} 1 & 1 & 1 \end{pmatrix} = \begin{pmatrix} 0 & 0 & 0 \end{pmatrix}, \\ \begin{pmatrix} 1 \end{pmatrix} \begin{pmatrix} 1 & 1 & 1 \end{pmatrix} = \begin{pmatrix} 1 & 1 & 1 \end{pmatrix}, \end{align} which is what we obtained before. In this way, we have an explicit encoding process for any code.
A code is specified entirely using a generator matrix.
Because the basis for the code $C$ is not unique, there can be many possible generator matrices for the same code $C$, and as we will see, some of matrices will have more calculational utility than others. We can convert between different generator matrices of the code by doing row operations on the generator matrix, which will not change the row space. Among the forms of the generator matrices, there is a standard form, which is when $G = [I_k| A]$, where $I_k$ is the $k\times k$ identity matrix and $A$ is a $k \times (n-k)$ matrix. The standard form can be obtained via row operation from any other form.
Hamming codes#
The repetition code is a very simple code. To understand more concepts about error-correction, we need to a more complex code. The Hamming code, invented by Richard Hamming, serves this purpose. It is a $[7,4,3]$ code, meaning messages of length $4$ are encoded into codewords of length $7$.
To define the Hamming code, we need to define the $\vec{C}$. First we define how to construct $\vec{c}$ from a $\vec{m}$. The first four bits of $\vec{c}$ are actually the same as $\vec{m}$, i.e. $$ c_0c_1c_2c_3 = m_0m_1m_2m_3. $$
The remaining bits, $c_4c_5c_6$ are defined by using the notion of parity.
The parity of a bit string is computed from the number of 1s in it. If there are even number of 1s, the parity of the string is said to be even or 0, otherwise it is odd or 1.
For example, the parity of $101$ is 0 and that of $01011$ is 1.
For the Hamming code, we compute the parity of various subsets of the message bits, and store them in the codeword. If the codeword is corrupted, some of the parities change, which allows us to identify the error. There are four message bits. There are $4C3 = 4$ subsets of size three. We compute the parity of three of these subsets. This is easily seen from the following diagram.
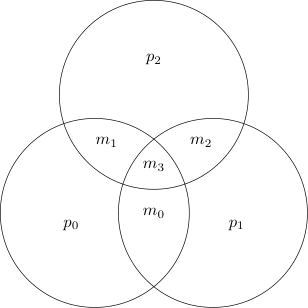
We see that
- $p_0$ is the parity of $m_0,m_1,m_3$,
- $p_1$ is the parity of $m_0,m_2,m_3$,
- $p_2$ is the parity of $m_1,m_2,m_3$.
The parity of the fourth subset ($m_0,m_1,m_2$) is dependent on the parity of the other three, so does not need to be computed. The full codeword is $$ \vec{c} = \begin{pmatrix} m_0 & m_1 & m_2 & m_3 & p_0 & p_1 & p_2 \end{pmatrix}. $$
Before we dig into the mathematics, let us discuss how the protocol works. Alice creates the codeword according to the prescription above and sends it to Bob. When Bob receives the corrupted codeword he computes the three parities of the first four bits ($\vec{\tilde{c}}_0, \vec{\tilde{c}}_1, \vec{\tilde{c}}_2, \vec{\tilde{c}}_3)$) and compares them with the last three bits of the corrupted codeword ($\vec{\tilde{c}}_4, \vec{\tilde{c}}_5, \vec{\tilde{c}}_6$). If some of the parities are different, then that indicates an error has occurred.
Suppose an error happens on $\vec{c}_0$. We can see from the diagram that this means that $p_0$ and $p_1$ will be flipped. On the other hand, an error on $\vec{c}_1$ will lead to $p_0$ and $p_2$ to be flipped. Similarly, if the error happens on a parity bit, then only that parity bit will be flipped. So a single parity bit differing indicates an error on it, while two or three parity bit differences indicate an error on the "message bits".
Task 1 (On paper)#
Fill out the following table.
| Error location | Parity bits flipped |
|---|---|
| $\vec{c}_0$ | |
| $\vec{c}_1$ | |
| $\vec{c}_2$ | |
| $\vec{c}_3$ | |
| $\vec{c}_4$ | |
| $\vec{c}_5$ | |
| $\vec{c}_6$ |
If there are no repeats in the second column, then Bob can always correct zero or one errors. What happens if two bits experience an error? Which parity bits flip if $m_0$ and $m_1$ experience an error? Compare with the table above.
Your answer should tell you that the Hamming code can only be used to protect against one error.
Generator matrix#
We now construct the generator matrix $G$ for the Hamming code, using the description above. The first four bits have to be copied as is, so the first four columns of $G$ must be the identity matrix. The next three columns must be the various ways of summing up the data bits. Hence, we get \begin{equation} G = \begin{pmatrix} 1 & 0 & 0 & 0 & 1 & 1 & 0 \\ 0 & 1 & 0 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \\ \end{pmatrix}. \end{equation} This is clearly in the standard form.
Task 2#
Complete the function hamming_encode that when passed a bit string, encodes it according to the Hamming code.
- Parameters:
messageanumpy.array, of shape (1,4) anddtype=intguaranteed to only contain 0 or 1.
- Returns:
- A
numpy.arrayof shape (1,7) anddtype=intthat is the the encoded version of themessage
- A
# a function to create random messages
from random import randint
import numpy as np
def random_message(k):
return np.array([randint(0,1) for _ in range(k)], dtype=int)
random_message(4)G = np.array([
[ 1 , 0 , 0 , 0 , 1 , 1 , 0 ],
[ 0 , 1 , 0 , 0 , 1 , 0 , 1 ],
[ 0 , 0 , 1 , 0 , 0 , 1 , 1 ],
[ 0 , 0 , 0 , 1 , 1 , 1 , 1 ]], dtype=int)
def hamming_encode(message):
pass
m = random_message(4)
c = hamming_encode(m)
print('m = ', m)
print('c = ', c)Identifying and correcting errors systematically#
The previous section provided us with a way of encoding any message $m$ into a codeword $c$ which generalizes to any code. Now, we discuss a systematic method to identify and possibly correct errors that occur when the codeword is sent through the noisy channel.
Suppose that Bob receives the block $\vec{\tilde{c}}$. This block could or could not be corrupted in some way. Every code has a certain tolerance for how many errors it can correctly identify and subsequently correct. The way to see it is to recall that $\vec{\tilde{c}} = \vec{c} + \vec{e}$. The error vector $\vec{e}$ is $n$ bits long, so there are $2^n$ possible errors. The codeword $\vec{c}$ has some information stored inside it to help identify the error. But it also has to store the message itself. So out of the $n$ bits of information in $\vec{c}$, $k$ bits of information is storing the message, while $n-k$ bits of information is available to identify errors. So, the code can at most identify $2^{n-k}$ different errors. For example, the repetition code can identify $2^{3-1} =$ four different errors - either no error or an error on exactly one of the three bits. Similarly, the Hamming code can identify $2^{7-4} =$ eight different errors.
What is the generic process for this? We saw in the Hamming code example that we stored some consistency checks on the message as part of our codeword. We said that the first four bits must obey some parities. Generally, in any linear code, there will be some consistency checks and will be given by a linear set of equations on the elements on the codeword. These equations are specified by a matrix multiplying the codewords, and given as follows.
The matrix $H \in \mathbb{F}_2^{(n-k) \times n}$ is a parity-check matrix for code $C$ if $C = \set{\vec{x} \in \mathbb{F}_2^n: H\vec{x}^T = 0}$.
This definition is saying that a code consists of all the elements of the codespace that satisfy the constraint $H\vec{x}^T = 0$. As there are $n-k$ rows to this matrix, the matrix places $n-k$ constraints on the elements of the codespace, leaving behind a $n - (n-k) = k$-dimensional space. Note that a system of linear equations can be linear transformed into another set of equivalent equations. Therefore, the parity-charity matrix is not unique. Row operations will yield other parity-check matrices for the same code.
The constraints in the parity-check matrix are obviously not independent from the generator matrix, as the generator matrix contains all the information about the code. The relationship between the generator matrix and the parity-check matrix is given as follows.
Lemma: A generator matrix $G$ and a parity-check matrix $H$ of a code $C$ are constrained by $HG^T = 0$.
Proof: Recall that any codeword $c = mG$, so $c^T = G^Tm$. Now, by the definition of $H$, we have $Hc^T= 0$, or $HG^Tm = 0$. But this last statement is true for all $m$, which is only possible if $HG^T=0$.
The above theorem only tells us if a parity-check matrix is valid for a code. It does not give us an explicit procedure for constructing it. The following lemma gives a process for exactly this, using the generator matrix in standard form.
Lemma: If $G$ is in standard form, i.e. $G = [I_k|A]$, then the parity-check matrix is $H = [A^T | I_{n-k}]$, where $I_k$ is $k \times k$, $A$ is $k \times (n-k)$, $A^T$ is $ (n-k) \times k$ and $I_{n-k}$ is $(n-k) \times (n-k)$.
Proof: We need to show that $HG^T= 0$. We can compute, \begin{equation} HG^T= \begin{pmatrix} A^T & I_{n-k} \end{pmatrix} \begin{pmatrix} I_k \\ A^T \end{pmatrix} = A^TI_k + I_{n-k}A^T = A^T + A^T = 0. \end{equation} Hence, proved.
For the Hamming code, the parity check matrix is \begin{equation} H=\begin{pmatrix} 1 & 1 & 0 & 1 & 1 & 0 & 0 \\ 1 & 0 & 1 & 1 & 0 & 1 & 0 \\ 0 & 1 & 1 & 1 & 0 & 0 & 1 \\ \end{pmatrix}. \end{equation}
Question: Verify that $HG^T = 0$ for the Hamming code.
H = np.array([
[1, 1, 0, 1, 1, 0, 0],
[1, 0, 1, 1, 0, 1, 0],
[0, 1, 1, 1, 0, 0, 1]], dtype=int)Error syndromes#
We have learned that the parity-check matrix can be used to determine if $\vec{\tilde{c}}$ is a codeword or not. But how can we compute which error has occurred. Imagine Alice sends the codeword $\vec{c}$ and it gets distorted to $\vec{\tilde{c}} = \vec{c} + \vec{e}$. Now, the effect of the parity-check matrix is, \begin{equation} \vec{s} = H\vec{\tilde{c}}^T = H\vec{c}^T + H\vec{e}^T = 0 + H\vec{e}^T = H\vec{e}^T. \end{equation} The quantity $\vec{s}$ is called an error syndrome, and is a vector of length $n-k$. There are $2^{n-k}$ possible error syndromes. We argued above that a classical linear code can only correct up to $2^{n-k}$ errors. Each correctable error corresponds to a distinct error syndrome.
For example, for the Hamming code, $\vec{s}$ will be of length 3 and there will 8 different syndromes corresponding to the different zero bit or one bit errors. The next few exercises will help you compute them.
Task 3#
Complete the function noise_channel that with probability p, flips each element of the input.
- Parameters:
c: anumpy.arrayof shape (1,n) anddtype=intguaranteed to only contain 0 or 1. The transmitted codeword.p:floatguaranteed to be between 0 and 1 inclusive. The probability of error.
- Returns:
numpy.arraryof shape (1,n) anddtype=intguaranteed to only contain 0 or 1. The corrupted codeword.
def noise_channel(c, p):
pass
c = random_message(7)
corrupted_c = noise_channel(m, 0.5)
print('corrupted c = ', corrupted_c)Task 4#
Complete the function hamming_syndrome that when passed a corrupted codeword, determines the error syndrome.
- Parameters:
corrupted_c: anumpy.array, of shape (1,7) anddtype=intguaranteed to only contain 0 or 1.
- Returns:
- Error syndrome: a
numpy.arrayof shape (1,3) anddtype=intthat is the error syndrome
- Error syndrome: a
def hamming_syndrome(corrupted_c):
passCorrecting the error#
Once one knows the error $\vec{e}$ that has occured, to correct the codeword, one can simply note that $\vec{\tilde{c}} + \vec{e} = \vec{c} + \vec{e} + \vec{e} = \vec{c}$. So the codeword is straightforwardly obtained.
Task 5#
Compute a dict of all possible syndromes and their corresponding one bit errors.
# write your code here
# key is syndrome
# value is the error
error_syndromes = dict()
# np.arrays can't be keys for dict
# So we need to convert them to tuples
# zero error case
s = np.array([0,0,0], dtype=int)
e = np.array([0,0,0,0,0,0,0], dtype=int)
error_syndromes[tuple(s)] = e
print(error_syndromes[tuple(s)])Task 6#
Complete the function hamming_correct that when passed a corrupted codeword, identifies the error syndrome, infers an error, and corrects for it.
- Parameters:
corrupted_c: anumpy.array, of shape (1,7) anddtype=intguaranteed to only contain 0 or 1. - Returns:
The corrected codeword, anumpy.arraryof shape (1,7) anddtype=intguaranteed to only contain 0 or 1.
def hamming_correct(corrupted_c):
pass