Error-correction by repetition#
Classical error-correction is a rich and old field which has produced many procedures for error-correction. To begin our journey through this field, we will start with the simplest possible method of error-correction. This method is called repetition code. The term 'code' refers to a mathematical object, which we will look at in more detail later on. For now, we will concentrate on what Alice and Bob do.
When Alice and Bob don't use any error correction#
Let us go back to scenario we created last time, and concretely work out what happens when Alice and Bob don't use any error correction.
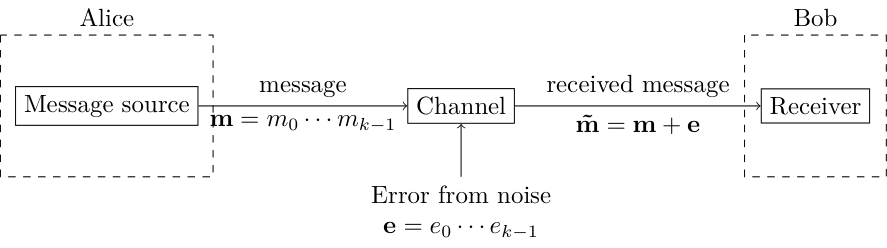
Alice wants to transmit a length-$k$ message $\vec{m}$, which is a sequence of bits. When she sends it, it gets distorted by noise $\vec{e}$, and what Bob receives is $\vec{\tilde{m}} = \vec{m} + \vec{e}$.
In general $\vec{e}$ can be any bit string, but lets define a simple yet realistic model for the kind of transmission noise we encounter in the real world. We assume that if we send a bit $m_i$ through the channel, with probability $p$ the bit will be flipped, and with probability $1-p$ it is not flipped. If we send multiple bits through the channel, each one is independently flipped with probability $p$. This means that \begin{equation} e_i = \begin{cases} 1 \quad\text{with prob $p$},\\ 0 \quad\text{with prob $1-p$}, \end{cases} \end{equation} where the value of each $e_i$ is independently set from the others.
Now, suppose that Bob receives the message $\vec{\tilde{m}} = 100$ from Alice. What can Bob infer from this? He doesn't know if any of the bits were flipped, so he can't say for sure that this is indeed the message that Alice wanted to send. The most he can infer is that each bit has $1-p$ chance of not getting flipped, so there is a $(1-p)^3$ that he received the right message. On the other hand, there is a $1-(1-p)^3$ chance he received the wrong message.
Can Alice and Bob do better?#
To do better, Alice and Bob must do something other than just sending the message. The simplest process is one you are already familiar with, if you have ever talked to someone on the phone with a bad connection. To make sure they hear what you have to say, you repeat yourself a few times. More abstractly, you usually send a longer message from which it is easier for the person on the other end to infer what you said correctly. This abstract process is shown below.

Instead of sending $\vec{m}$, Alice transforms her message into a longer bit-string called the codeword $\vec{c}$. This process is called encoding. She then sends this through the channel. On the other end, Bob receives a corrupted codeword $\vec{\tilde{c}}$. He subjects it to a process called decoding. If all goes well, then with higher probability than $(1-p)^k$, he will recover the correct message, i.e. $\vec{\hat{m}} = \vec{m}$. However, note that there will always be some non-zero chance of making a mistake, $\vec{\hat{m}} \ne \vec{m}$.
Detecting and correcting by repetition#
The process of detecting and correcting errors by repetition is as follows. Alice takes each bit $m_i$ in the message one by one. For each bit, if it has value $0$, Alice sends the block of bits $000$, and if it has value $1$, Alice sends the block $111$. Therefore, the codeword $\vec{c}$ will have length $n=3k$.
An alternate notation we will use throughout this book is to write messages with a bar on top, and write the codeword without any bars. For example, here we can simply write $$ \bar{0} = 000, \quad \bar{1} = 111. $$
Using the above process if the message is $\overline{1010}$ then Alice sends $111000111000$.
Suppose, that Bob receives the corrupted code-stream $101100111000$, in which the second and fourth bits have been flipped by the noisy channel. He, of course, doesn't know which bits have been flipped.
To correct any errors, he will apply a majority voting algorithm to each block of three bits in the corrupted codeword. The first block is $101$, and since there are two 1s in it and one 0, he infers that the first sent bit is likely to be $\overline{1}$. Similarly, he infers from the second, third and fourth blocks of three, that the second, third and fourth bits are likely to be 0, 1 and 0, respectively. Hence, he correctly decodes the message to message was $\overline{1010}$.
Notice that this method only works if there is at most one bit flip in each block of three. If there are two or more flips in a block, then Bob inferred bit string will be different from the one Alice intended to send. For example, if the corrupted code-string was $101110111000$, then using the same algorithm Bob infers that that message was $1110$.
Question: What is the encoding of $\overline{011}$?
To make sure you understand the above process, you will now implement it as computer code.
Task 1#
Complete the function repetition_encode that when passed a bit string, encodes it according to the repetition code.
- Parameters:
message: astrof any length, guaranteed to only contain 0 or 1. - Returns:
codeword: astrthat is the the encoded version of themessage. Must have length three times the length ofmessage.
def repetition_encode(data_stream):
pass# check your solution
k = 3
for i in range(2**k):
message = bin(i)[2:].zfill(k)
codeword = repetition_encode(message)
print(message, codeword)The process the Bob uses to check and correct for errors is called decoding.
Task 2#
Complete the function repetition_decode that when passed a corrupted codeword, decodes it according to the repetition code. This include identifying any errors and correcting for them.
- Parameters:
codeword: astr, guaranteed to only contain 0 or 1, and length divisible by 3. - Returns:
estimated_message: astrthat is the the decoded version of thecodeword
def repetition_decode(codeword):
passHere is a script that generates random messages, run them though the encoder, then corrupts the result, and finally decodes them. Use this to check your answers. Remember that if there are multiple error per block then, the estimated message should not be equal the original message.
from random import randint, random
# these are the two parameters we need to set
message_length = 5
p = 0.1
# create a random message
message = ''.join([str(randint(0,1)) for i in range(message_length)])
print('message = ', message)
# encode the message
codeword = repetition_encode(message)
print('codeword = ', codeword)
# send it through the noisy channel
corrupted_codeword = ''
for c in codeword:
if random() < p:
if c == '0':
corrupted_codeword += '1'
else:
corrupted_codeword += '0'
else:
corrupted_codeword += c
print('corrupted_codeword = ', corrupted_codeword)
# decode it
estimated_message = repetition_decode(corrupted_codeword)
print('estimated_message = ', estimated_message)
print('Is message = estimated_message?', message == estimated_message)How good is the repetition based process?#
Whenever we come across an error-correction process, we should evaluate how effective it is at correcting errors. The following tasks help you figure this out on your own.
Task 3 (On paper)#
Using the repetition code, what is the probability that Bob correctly infers the correct bit-string? Each block of three is treated separately, so we only need to estimate the probability of correct inference from each block. Let $p$ be the probability of error on a single bit. Let the probability of an error on each bit be independent.
What is the probability of
- zero errors,
- one error,
- two errors,
- three errors.
Don't forget the multiplicities.
Task 4#
Consider the case of when Alice and Bob do not use any error correction process. Then if Alice sends a single bit, the probability of Bob infering the wrong bit against the physical probability of error $p$ is as follows. Obviously, it's a straight line.
import matplotlib.pyplot as plt
import numpy as np
# probability of error on transmitted bit
p = np.linspace(0, 1, 100)
# probability of incorrect inference by Bob
pr_of_incorrect_inference = p
_, ax = plt.subplots(figsize=(5, 5), layout='constrained');
ax.plot(p, pr_of_incorrect_inference);
ax.set_xlabel('probability of error on transmitted bit');
ax.set_ylabel('probability of incorrect inference by Bob');
When Alice and Bob do use error correction, plot the probability of incorrect inference by Bob vs the probability of error on a single bit $p$. Keep the line drawn above, so you can compare the two cases. For what values of $p$ is it beneficial to use error correction?
# your calculation code here
_, ax = plt.subplots(figsize=(5, 5), layout='constrained');
ax.plot(p, pr_of_incorrect_inference, label='no error correction');
# you can uncomment the line below to add another plot to the same figure
ax.plot(p, pr_of_incorrect_inference_repetition, label='with repetition code');
ax.set_xlabel('probability of error on transmitted bit');
ax.set_ylabel('probability of incorrect inference by Bob');
plt.legend();What you will discover is that when the physical error rate $p$ is low, then the repetition code helps. However if $p$ is large then using the repetition code is actually worse than the naive process. Can you argue why?
Task 5 (On paper, optional)#
This exercise will become crucial when we later discuss fault-tolerant quantum computing.
Suppose that Alice has some encoded message. She wants to do some logical operations on the encoded message without decoding it first. How can she go about it? Concretely, how can she apply
- A NOT operation, that takes $\bar{0}$ to $\bar{1}$, and $\bar{1}$ to $\bar{0}$.
- An OR operation, that has the following truth table
| Input | Output |
|---|---|
| $\overline{00}$ | $\overline{0}$ |
| $\overline{01}$ | $\overline{1}$ |
| $\overline{10}$ | $\overline{1}$ |
| $\overline{11}$ | $\overline{1}$ |